最近读到一篇有意思的论文 On the Origin of Algorithmic Progress in AI,结论有点出乎意料。
从2012到2023年,训练同样性能的模型,需要的算力降低了大约22,000倍。
这个数字挺夸张的。那这22,000倍的提升是怎么来的?论文作者做了一堆实验,把Transformer里那些”现代改进”一个个拆开来看 - SwiGLU激活函数、RoPE位置编码、各种Norm层、学习率调度、Adam优化器等等。
结果发现了些意外的东西。
小改进的贡献没那么大
论文作者在小规模模型(360万参数)上做了实验,测试了各种”现代改进”的实际效果:
- SwiGLU激活函数:1.17倍
- RoPE位置编码:1.44倍
- Pre-RMSNorm归一化:1.87倍
- AdamW优化器(相比SGD):1.87倍
- 学习率调度:几乎没区别(<1.05倍)
把这些改进全加起来,效率提升不到10倍。那剩下的2000多倍从哪来的?
Transformer的规模效应
Transformer不是一开始就吊打LSTM的,而是越大越强。
小规模时(10¹⁵ FLOPs),Transformer比LSTM强6.28倍,优势不算特别明显。但随着规模增长,这个优势会越来越大。
也就是说,算力不够的话,你根本看不出Transformer有多强。
Chinchilla也是类似。Kaplan scaling是模型大数据少,Chinchilla是模型和数据等比例增长。大规模下Chinchilla明显更省算力,但小规模时差别不大。
论文最后算出,能解释的效率提升大约是6,930倍(不是之前估计的22,000倍)。更关键的是,这6,930倍里有91%来自两个规模依赖的变化:
- LSTM到Transformer的架构转变(贡献了68%)
- Kaplan到Chinchilla的scaling策略调整(贡献了剩余的大部分)
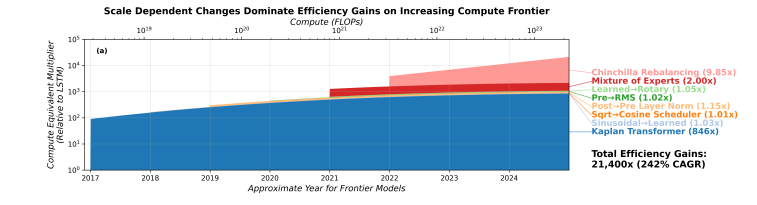
图:AI效率提升的来源 - 规模依赖的架构变化占主导
所以
过去十来年AI的飞跃,主要不是靠那些精巧的训练技巧堆出来的,而是靠少数几个只有在大规模下才能发挥作用的结构性变化。

工业革命后的GDP增长曲线 - 真正的质变来自生产方式的根本变革
没有足够的算力,很多”先进算法”的优势根本体现不出来。小规模下看着有效的改进,放到工业规模可能也就那样。
小的算法改进当然也有价值,但想要质的飞跃,还是得靠那些能在大规模下发挥作用的创新,以及支撑这些创新的算力。
技术发展从来都不是线性的。工业革命之前,人类发展了几千年,工艺不断进步,工匠技艺越来越好,但本质上生产力没提升多少。真正的质变来自蒸汽机、纺织机、炼钢技术这些生产方式的根本变革。
AI现在有点这个感觉。真正改变游戏的,不是那些小改进,而是在大规模下才能发挥优势的结构性变革,还有支撑这些变革的”蒸汽机”——算力。
说白了:力大砖飞。